Why parsing streams and not strings?
When I first discovered Node.js I had a hard time wrapping my head around the concept of streams and asynchronous programming. Gladly, this didn’t last long and I soon understood the power of streaming logic.
Working with streams involves doing things as they come, as fast as possible. No postponing is allowed. Now that I’m writing this, I realize that I should perhaps consider most things in life as a stream…
Anyway, I had this idea that I should write some utilities to help while streaming text (mostly) in order to get the meaning out of it without waiting to have it stored in a huge string object in memory. These are the three modules that came out of this idea.
Doing it step by step
Some time ago, I had been working with CodeMirror which is an awesome tool for dynamic syntax highlighting in the browser. My project with it involved writing a C/C++ parser, which I started off the existing Javascript parser. This was the first time I heard about the vocabulary of parsing. Also CodeMirror, for performance reasons, expose a very streamy API.
From this, I learned that it’s usually best to split your parsing logic in two components: a Tokenizer and a Parser.
Tokenizer
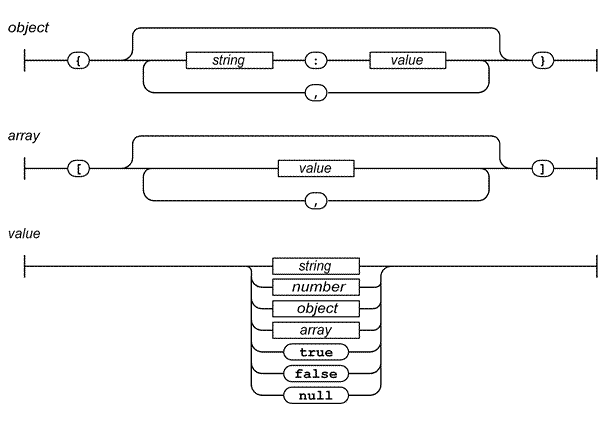
The role of the tokenizer is to read the raw data, which is usually a bunch of characters strings, and group those in somewhat meaningful packets called tokens. Tokens usually have a name or type and a content. The type of the token is its nature, what kind of word it is. The content is obviously what is actually contained in the string.
Let’s have a very simple example. Take the sentence “My silly kitten is here”. One could tokenize it this way:
[
{type:"possessive", content:"my"},
{type:"adjective", content: "silly"},
{type:"name", content:"kitten"},
{type:"verb", content:"is"},
{type:"location", content:"here"}
]
This might remind you of what you learned in school. The purpose of a tokenizer is to group bits of the input string together and determine what they can be used for while preserving order.
Parser
The role of the parser is to take a series of tokens as input and extract actual meaning from it. The meaning you extract from it is your business, it can be pure data, instructions, actions, calls, requests, etc.
Whereas the tokenizer tries to detect the nature of the tokens, the parser tries to determine the role of the tokens. It can also link the tokens together, if they are expected in a certain order for example.
Let’s take a trivial example. given this series of tokens:
[
{type:"number", content:2},
{type:"string", content:"Hello"},
{type:"string", content:"world"}
]
The role of the parser could be to first expect a number, read it, then read that same number of strings coming after
the previously read number. It’s usually the parser that gives errors when it encounters tokens which it didn’t expect.
You’ve probably seen a million times errors like PARSE ERROR: UNEXPECTED TOKEN... And I’m pretty sure that you are eager
to emit this kind of errors yourself in order to annoy the hell out of your users.